We are interested in studying and developing vision-based
systems that can navigate and interact with complex,
uncontrolled and dynamic environments. A short summary of
the most relevant projects that we have developed in this
direction is available here below.
|
Computational Photography
Beyond pixels 
Computational photography is a new emerging
field that combines computing, digital sensor
design, and controlled illumination to enable novel
imaging applications. One can enhance the dynamic
range of the sensor, digitally vary focus,
resolution, and depth of field, analyze reflectance
and lighting. These are only some of the
applications that are made possible by
computational photography and that we are
interesting in exploring.
Our light field camera and the superresolution project |
|
|
|
Supervised Classification
Transformation Invariance 
The classification of objects in images
requires invariance to changes in their scale,
orientation, location, and in their photometry, due
to varying illumination and noise. One way to
address such classification problem is to
incorporate invariance to these changes at
run-time. This approach however is limited by the
discretization of the class of transformations and
by the number of independent transformations that
require invariance. Rather, we consider
incorporating invariance during training. We avoid
enlarging the training set by adding so-called
virtual samples, i.e., samples obtained by morphing
the original data set for a finite set of
transformations, and instead incorporate invariance
in the classification error function used for
training. Given a sample, one can compute in
analytic form the error of a classifier against a
distribution of a set of transformations. This is,
for example, the approach used in Vicinal Risk
minimization and we formulate it in the boosting
framework.
|
|
|
|
Real-Time Structure from Motion and Virtual
Object Insertion
Robustness to outliers 
Interacting with a complex, unknown, dynamic
environment requires continuously updated knowledge
of its shape and motion and robustness to unmodeled
events. We propose several algorithms aimed at
inferring shape, motion and appearance causally and
incrementally. Once motion and shape are accurately
inferred, then one can insert computer graphics
objects or animations in the real scene in
real-time.
|
|
|
|
3D Estimation and Image Restoration
Exploting defocus and motion-blur 
Images contain several cues that allow us to
infer spatial properties of the scene being
depicted. For example, texture, shading, shadows,
silhouettes are all pictorial cues that, when
coupled with suitable prior assumptions, allow one
to infer spatial properties of the scene. In
addition to pictorial cues, which are present in
one single image, one can exploit cues that make
use of multiple images. One such a cue is defocus,
where images are captured by changing the focus
setting of the camera. By doing so, objects at
different depth appear blurred in different ways.
Similarly, objects moving with different motion
produce different motion-blurred images, and
therefore images can be exploited for the inverse
problem of inferring shape and motion.
|
|
|
|
Shape, Reflectance and Illumination
Estimation
Non-Lambertian surfaces 
Measuring the 3d surface of a scene is
challenging because images vary greatly with the
material and the geometry of the surfaces, the
illumination conditions of the scene and the
geometry of the sensor. The main challenge is in
establishing correspondence between regions in the
images that are projections of the same object. One
way to simplify this problem is to assume that all
objects are Lambertian, i.e. such that their
appearance does not change with the vantage point.
The immediate consequence of such assumption is
that correspondence can be established by direct
comparison of images, thus bypassing the estimation
of light sources and reflectance of the surfaces.
However, in nature a large number of materials are
non Lambertian. For instance, polished metal,
plastic, porcelain, marble, skin and varnished
surfaces are non Lambertian. We propose to exploit
occlusion boundaries to recover the illumination of
the scene and the reflectance of the objects, as
they provide strong geometric cues that are robust
to changes in the appearance due to camera
motion.
|
|
|
Segmentation of Dynamic Textures

Natural events, such as smoke, flames or water
waves, exhibit motion patterns whose complexity can
hardly be captured by tracking every pixel. What
one could do, for instance, is to capture the
stochastic properties of such events. One way to do
so, is to employ the so-called dynamic textures.
Furthermore, video sequences might simultaneously
depict multiple natural events that are
"stochastically homogeneous" only within a certain
unknown region. Finding such regions is the problem
of dynamic texture segmentation.
|
|
|
Retinal Imaging: Monocular or Stereo Fundus
Camera?
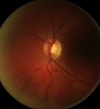
Glaucoma progression causes optic nerve fibers
atrophy and changes in the three-dimensional (3D)
shape of the optic disc. The most common clinical
routine for glaucoma patients is the examination of
the optic nerve head. To this purpose one can
employ two-dimensional (2D) or 3D imaging
modalities. 2D imaging can be provided by monocular
fundus cameras, while 3D imaging can be provided,
for example, by stereo fundus cameras, Heidelberg
scanning laser tomography, scanning laser
polarimetry, and optical coherence tomography. We
consider only monocular and stereo fundus cameras,
which are the most accessible 3D imaging systems.
Furthermore, as 2D imaging is based on 2D visual
cues, which may be prone to misjudgement, we focus
our analysis on 3D imaging only. We show that
traditional monocular systems do not provide depth
information of the retina and hence they cannot be
used in place of stereo systems. We also
experimentally determine the maximum accuracy
achievable by a stereo system and show its
suitability for assessing glaucoma.
|